
Short bio: Yanbin Liu is a Senior Lecturer (US Associate Professor) at the School of Engineering, Computer and Mathematical Sciences, Auckland University of Technology (AUT).
Before joing AUT, he was a Research Fellow at the School of Computing, Australian National University, working with Prof. Stephen Gould.
Earlier, his research journey included a Research Fellow jointly with the Harry Perkins Institute of Medical Research and the Department of Computer Science and Software Engineering at the University of Western Australia, working with Winthrop Prof. Mohammed Bennamoun and Prof. Girish Dwivedi.
Prior to this, he contributed was a Postdoc at the University of Technology Sydney (UTS), working with Prof. Ling Chen.
He earned his PhD from the Australian Artificial Intelligence Institute (AAII), UTS, under the supervision of Prof. Yi Yang.
Before embarking on his doctoral studies, he earned his BE and MS degress from Tianjin University, guided by Prof. Yahong Han and Prof. Jianmin Jiang.
Research interests: Deep learning under limited labels and distribution shifts, with applications to:
(1) Few-shot learning and meta-learning,
(2) Spatial-temporal modeling, and
(3) Medical imaging and brain-inspired neural networks.
Prospective students: I am looking for self-motivated PhD students with a strong CS/Math/ML background to study at the Auckland University of Technology (AUT).
Email: yanbin.liu@aut.ac.nz
News
Research (selected papers)
See Google Scholar profile for a full list of publications.
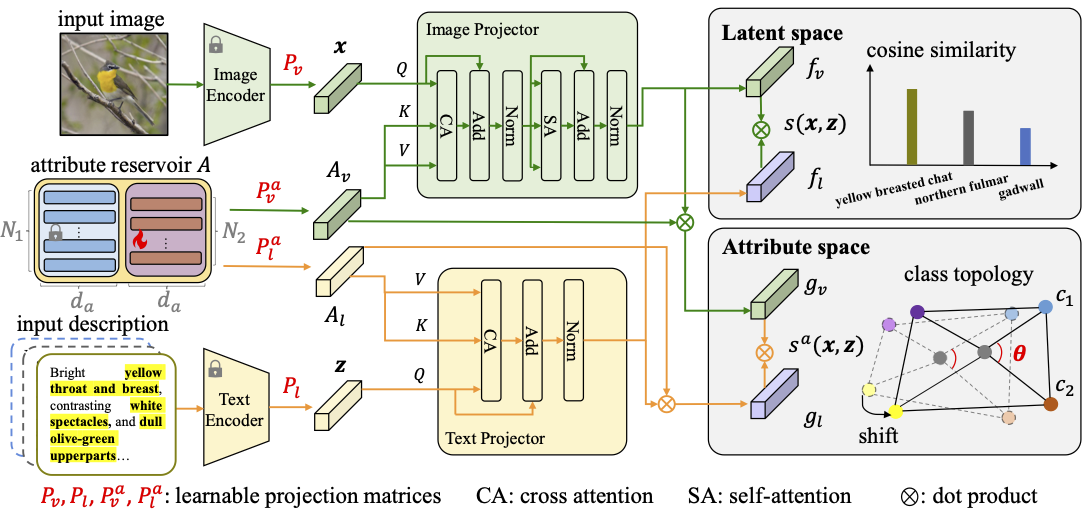
Hui Chen, Yanbin Liu, Yongqiang Ma, Nanning Zheng and Xin Yu
Neural Information Processing Systems (NeurIPS) 2024.
@inproceedings{Chen:NeurIPS2024,
author = {Hui Chen and
Yanbin Liu and
Yongqiang Ma and
Nanning Zheng and
Xin Yu},
title = {TPR: Topology-Preserving Reservoirs for Generalized Zero-Shot Learning},
booktitle = {NeurIPS},
year = {2024}
}
Pre-trained vision-language models (VLMs) such as CLIP have shown excellent performance for zero-shot classification. Based on CLIP, recent methods design various learnable prompts to evaluate the zero-shot generalization capability on a base-to-novel setting. This setting assumes test samples are already divided into either base or novel classes, limiting its application to realistic scenarios. In this paper, we focus on a more challenging and practical setting: generalized zero-shot learning (GZSL), i.e., testing with no information about the base/novel division. To address this challenging zero-shot problem, we introduce two unique designs that enable us to classify an image without the need of knowing whether it comes from seen or unseen classes. Firstly, most existing methods only adopt a single latent space to align visual and linguistic features, which has a limited ability to represent complex visual-linguistic patterns, especially for fine-grained tasks. Instead, we propose a dual-space feature alignment module that effectively augments the latent space with a novel attribute space induced by a well-devised attribute reservoir. In particular, the attribute reservoir consists of a static vocabulary and learnable tokens complementing each other for flexible control over feature granularity. Secondly, finetuning CLIP models (e.g., prompt learning) on seen base classes usually sacrifices the model's original generalization capability on unseen novel classes. To mitigate this issue, we present a new topology-preserving objective that can enforce feature topology structures of the combined base and novel classes to resemble the topology of CLIP. In this manner, our model will inherit the generalization ability of CLIP through maintaining the pairwise class angles in the attribute space. Extensive experiments on twelve object recognition datasets demonstrate that our model, termed Topology-Preserving Reservoir (TPR), outperforms strong baselines including both prompt learning and conventional generative-based zero-shot methods.
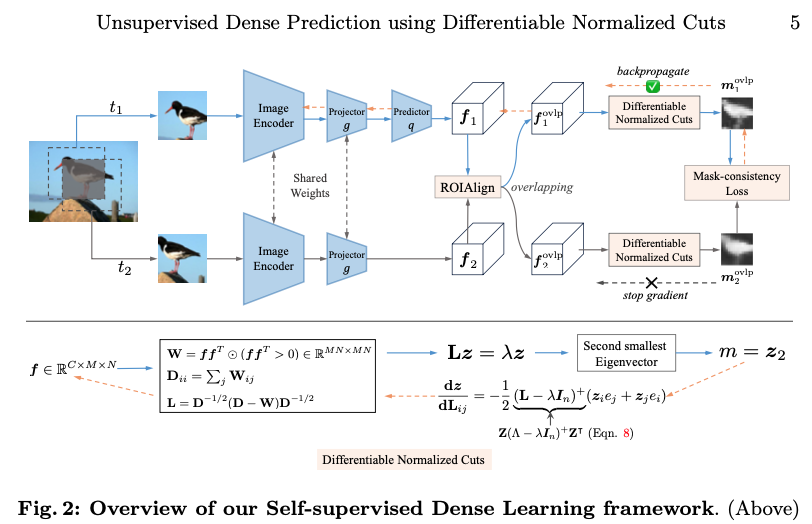
Yanbin Liu, and Stephen Gould
European Conference on Computer Vision (ECCV) 2024.
@inproceedings{Liu:ECCV2024,
author = {Yanbin Liu and
Stephen Gould},
title = {Unsupervised Dense Prediction using Differentiable Normalized Cuts},
booktitle = {ECCV},
year = {2024}
}
With the emergent attentive property of self-supervised Vision Transformer (ViT), Normalized Cuts (NCut) has resurfaced as a powerful tool for unsupervised dense prediction. However, the pre-trained ViT backbone (e.g., DINO) is frozen in existing methods, which makes the feature extractor suboptimal for dense prediction tasks. In this paper, we propose using Differentiable Normalized Cuts for self-supervised dense feature learning that can improve the dense prediction capability of existing pre-trained models. First, we review an efficient gradient formulation for the classical NCut algorithm. This formulation only leverages matrices computed and stored in the forward pass, making the backward pass highly efficient. Second, with NCut gradients in hand, we design a self-supervised dense feature learning architecture to finetune pre-trained models. Given two random augmented crops of an image, the architecture performs RoIAlign and NCut to generate two foreground masks of their overlapping region. Last, we propose a mask-consistency loss to back-propagate through NCut and RoIAlign for model training. Experiments show that our framework generalizes to various pre-training methods (DINO, MoCo and MAE), network configurations (ResNet, ViT-S and ViT-B), and tasks (unsupervised saliency detection, object discovery and semantic segmentation). Moreover, we achieved state-of-the-art results on unsupervised dense prediction benchmarks.
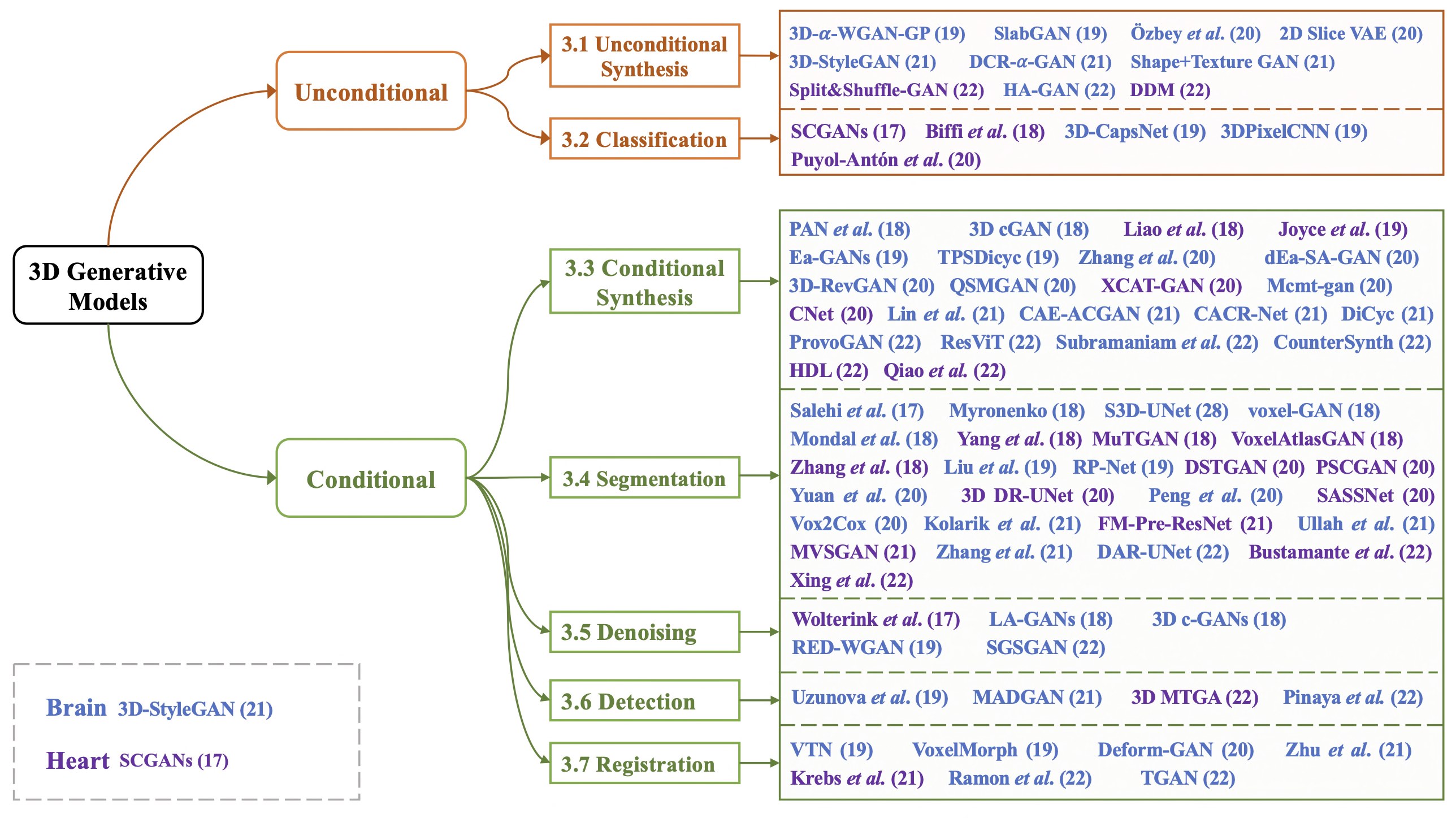
Yanbin Liu, Girish Dwivedi, Farid Boussaid, and Mohammed Bennamoun
ACM Computing Surveys (CSUR) 2024.
@article{Liu2023HeartBrain,
title = {3d brain and heart volume generative models: A survey},
author = {Liu, Yanbin and Dwivedi, Girish and Boussaid, Farid and Bennamoun, Mohammed},
journal = {ACM Computing Surveys},
volume = {56},
number = {6},
pages = {1--37},
year = {2024},
publisher = {ACM New York, NY}
}
Generative models such as generative adversarial networks and autoencoders have gained a great deal of attention in the medical field due to their excellent data generation capability. This paper provides a comprehensive survey of generative models for three-dimensional (3D) volumes, focusing on the brain and heart. A new and elaborate taxonomy of unconditional and conditional generative models is proposed to cover diverse medical tasks for the brain and heart: unconditional synthesis, classification, conditional synthesis, segmentation, denoising, detection, and registration. We provide relevant background, examine each task and also suggest potential future directions. A list of the latest publications will be updated on Github to keep up with the rapid influx of papers at https://github.com/csyanbin/3D-Medical-Generative-Survey.
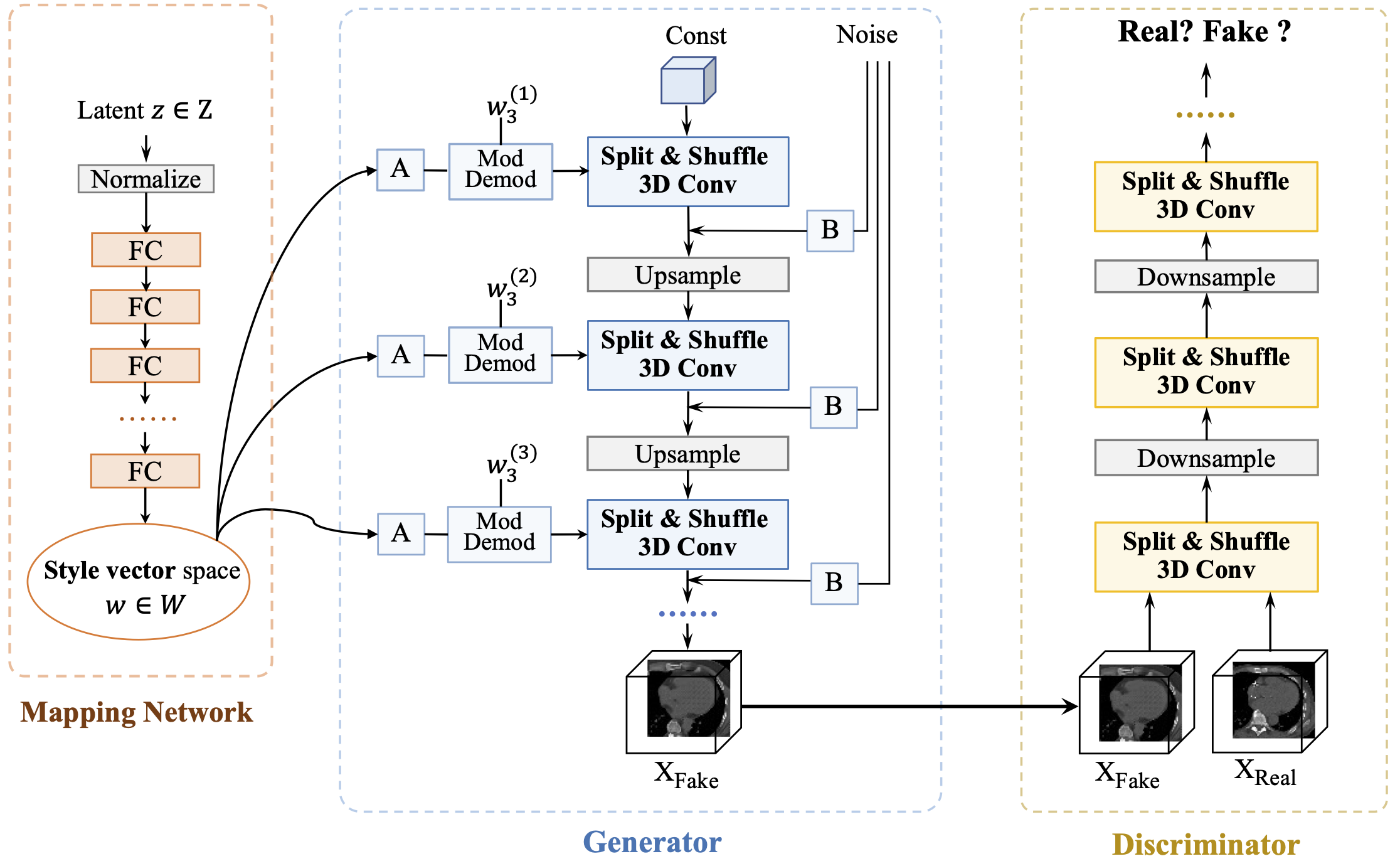
Yanbin Liu, Girish Dwivedi, Farid Boussaid, Frank Sanfilippo, Makoto Yamada and Mohammed Bennamoun
Computer Methods and Programs in Biomedicine 2023.
@article{liu2023inflating,
title = {Inflating 2D Convolution Weights for Efficient Generation of 3D Medical Images},
author = {Liu, Yanbin and Dwivedi, Girish and Boussaid, Farid and Sanfilippo, Frank and Yamada, Makoto and Bennamoun, Mohammed},
journal = {Computer Methods and Programs in Biomedicine},
pages = {107685},
year = {2023},
publisher = {Elsevier}
}
Background and Objective: The generation of three-dimensional (3D) medical images has great application potential since it takes into account the 3D anatomical structure. Two problems prevent effective training of a 3D medical generative model: (1) 3D medical images are expensive to acquire and annotate, resulting in an insufficient number of training images, and (2) a large number of parameters are involved in 3D convolution. Methods: We propose a novel GAN model called 3D Split&Shuffle-GAN. To address the 3D data scarcity issue, we first pre-train a two-dimensional (2D) GAN model using abundant image slices and inflate the 2D convolution weights to improve the initialization of the 3D GAN. Novel 3D network architectures are proposed for both the generator and discriminator of the GAN model to significantly reduce the number of parameters while maintaining the quality of image generation. Several weight inflation strategies and parameter-efficient 3D architectures are investigated. Results: Experiments on both heart (Stanford AIMI Coronary Calcium) and brain (Alzheimer’s Disease Neuroimaging Initiative) datasets show that our method leads to improved 3D image generation quality (14.7 improvements on Frchet inception distance) with significantly fewer parameters (only 48.5% of the baseline method). Conclusions: We built a parameter-efficient 3D medical image generation model. Due to the efficiency and effectiveness, it has the potential to generate high-quality 3D brain and heart images for real use cases.
Yanbin Liu, Linchao Zhu, Xiaohan Wang, Makoto Yamada and Yi Yang
IEEE Transactions on Neural Networks and Learning Systems (TNNLS) 2023.
@ARTICLE{TNNLS2023_BSSD,
author = {Liu, Yanbin and Zhu, Linchao and Wang, Xiaohan and Yamada, Makoto and Yang, Yi},
journal = {IEEE Transactions on Neural Networks and Learning Systems},
title = {Bilaterally-normalized Scale-consistent Sinkhorn Distance for Few-shot Image Classification},
year = {2023},
doi = {10.1109/TNNLS.2023.3262351}
}
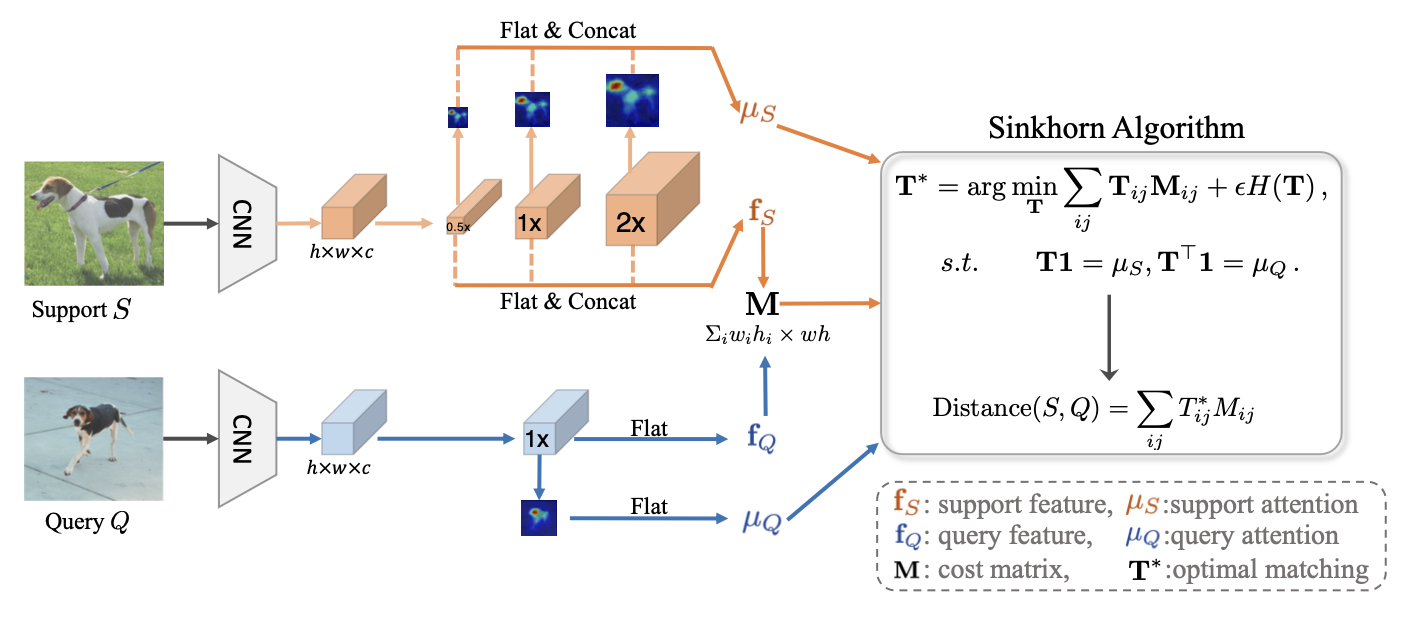
Abstract—Few-shot image classification aims at exploring transferable features from base classes to recognize images of the unseen novel classes with only a few labelled images. Existing methods usually compare the support features and query features, which are implemented by either matching the global feature vectors or matching the local feature maps at the same position. However, the few labelled images fail to capture all the diverse context and intra-class variations, leading to mismatch issues for existing methods. On one hand, due to the misaligned position and cluttered background, existing methods suffer from the object mismatch issue (Fig. 1(a)). On the other hand, due to the scale inconsistency between images, existing methods suffer from the scale mismatch issue (Fig. 1(b)). In this paper, we propose the Bilaterally-normalized Scale-consistent Sinkhorn Distance (BSSD) to solve these issues. Firstly, instead of same-position matching, we utilize the Sinkhorn Distance to find an optimal matching between images, mitigating the object mismatch caused by misaligned position. Meanwhile, we propose the intra-image and inter-image attentions as the bilateral normalization on Sinkhorn Distance to suppress the object mismatch caused by background clutter. Secondly, local feature maps are enhanced with the multi-scale pooling strategy, making Sinkhorn Distance possible to find a consistent matching scale between images. Experimental results show the effectiveness of the proposed approach, and we achieve the state-of-the-art on three few-shot benchmarks.
Jiahao Zhang, Anoop Cherian, Yanbin Liu, Yizhak Ben-Shabat, Cristian Rodriguez and Stephen Gould
CVPR 2023.
@inproceedings{Zhang2023Aligning,
author = {Zhang, Jiahao and Cherian, Anoop and Liu, Yanbin and Ben-Shabat, Yizhak and Rodriguez, Cristian and Gould, Stephen},
title = {Aligning Step-by-Step Instructional Diagrams to Video Demonstrations},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023},
}
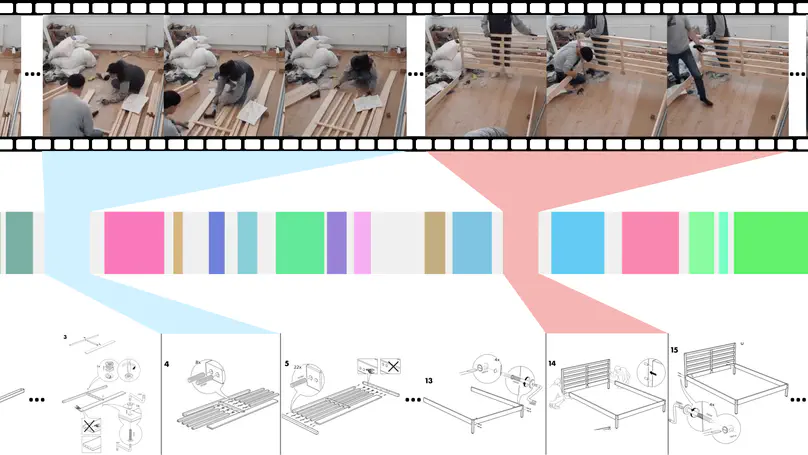
Multimodal alignment facilitates the retrieval of in- stances from one modality when queried using another. In this paper, we consider a novel setting where such an align- ment is between (i) instruction steps that are depicted as assembly diagrams (commonly seen in Ikea assembly man- uals) and (ii) segments from in-the-wild videos; these videos comprising an enactment of the assembly actions in the real world. We introduce a supervised contrastive learning ap- proach that learns to align videos with the subtle details of assembly diagrams, guided by a set of novel losses. To study this problem and evaluate the effectiveness of our method, we introduce a new dataset: IAW—for Ikea assembly in the wild—consisting of 183 hours of videos from diverse fur- niture assembly collections and nearly 8,300 illustrations from their associated instruction manuals and annotated for their ground truth alignments. We define two tasks on this dataset: First, nearest neighbor retrieval between video segments and illustrations, and, second, alignment of in- struction steps and the segments for each video. Extensive experiments on IAW demonstrate superior performance of our approach against alternatives.
Yanbin Liu, Juho Lee, Linchao Zhu, Ling Chen, Humphrey Shi and Yi Yang
ICCV 2021.
@InProceedings{Liu_2021_ICCV,
title = {A Multi-Mode Modulator for Multi-Domain Few-Shot Classification},
author = {Liu, Yanbin and Lee, Juho and Zhu, Linchao and Chen, Ling and Shi, Humphrey and Yang, Yi},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {8453-8462}
}
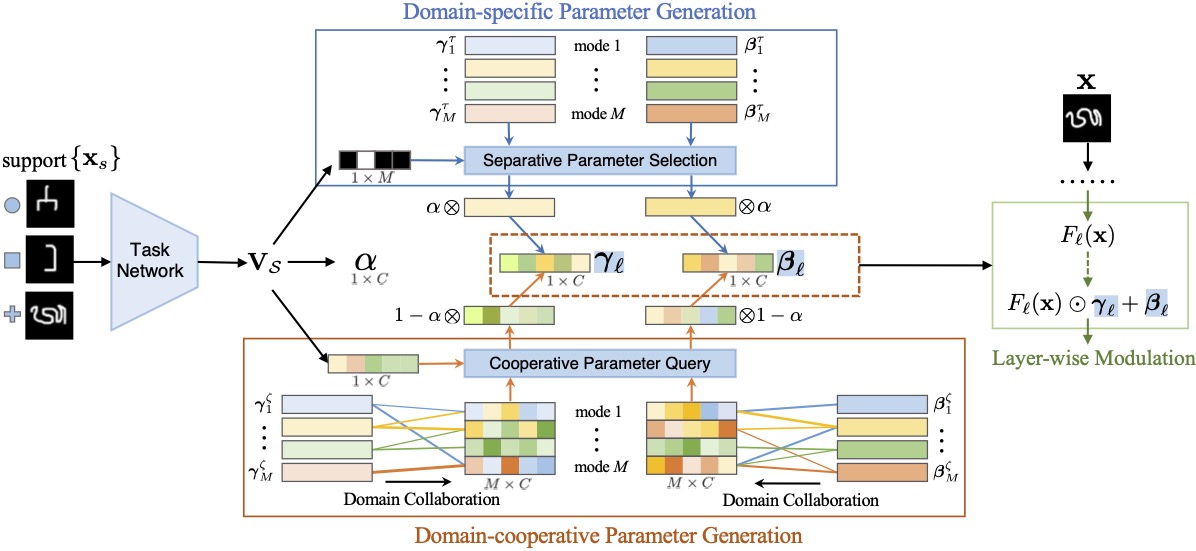
Most existing few-shot classification methods only consider generalization on one dataset (i.e., single-domain), failing to transfer across various seen and unseen domains. In this paper, we consider the more realistic multi-domain few-shot classification problem to investigate the cross-domain generalization. Two challenges exist in this new setting: (1) how to efficiently generate multi-domain feature representation, and (2) how to explore domain correlations for better cross-domain generalization. We propose a parameter-efficient multi-mode modulator to address both challenges. First, the modulator is designed to maintain multiple modulation parameters (one for each domain) in a single network, thus achieving single-network multi-domain representation. Given a particular domain, domain-aware features can be efficiently generated with the well-devised separative selection and cooperative query modules. Second, we further divide the modulation parameters into the domain-specific set and the domain-cooperative set to explore the intra-domain information and inter-domain correlations, respectively. The intra-domain information describes each domain independently to prevent negative interference. The inter-domain correlations guide information sharing among relevant domains to enrich their own representation. Moreover, unseen domains can utilize the correlations to obtain an adaptive combination of seen domains for extrapolation. We demonstrate that the proposed multi-mode modulator achieves state-of-the-art results on the challenging META-DATASET benchmark, especially for unseen test domains.

Yanbin Liu*, Makoto Yamada*, Yao-Hung Hubert Tsai, Tam Le, Ruslan Salakhutdinov and Yi Yang
ECML/PKDD 2021.
@INPROCEEDINGS{liu2019lsmi,
title = {LSMI-Sinkhorn: Semi-supervised Mutual Information Estimation with Optimal Transport},
author = {Liu, Yanbin and Yamada, Makoto and Tsai, Yao-Hung Hubert and Le, Tam and Salakhutdinov, Ruslan and Yang, Yi},
booktitle = {ECML/PKDD},
year = {2021}
}
Estimating mutual information is an important machine learning and statistics problem. To estimate the mutual information from data, a common practice is preparing a set of paired samples $\{(\boldx_i,\boldy_i)\}_{i = 1}^n \iid p(\boldx,\boldy)$. However, in many situations, it is difficult to obtain a large number of data pairs. To address this problem, we propose the semi-supervised Squared-loss Mutual Information (SMI) estimation method using a small number of paired samples and the available unpaired ones. We first represent SMI through the density ratio function, where the expectation is approximated by the samples from marginals and its assignment parameters. The objective is formulated using the optimal transport problem and quadratic programming. Then, we introduce the Least-Squares Mutual Information with Sinkhorn (LSMI-Sinkhorn) algorithm for efficient optimization. Through experiments, we first demonstrate that the proposed method can estimate the SMI without a large number of paired samples. Then, we evaluate and show the effectiveness of the proposed LSMI-Sinkhorn algorithm on various types of machine learning problems such as image matching and photo album summarization.
Yanbin Liu, Linchao Zhu, Makoto Yamada and Yi Yang
CVPR 2020.
@INPROCEEDINGS{liu2020semantic,
title = {Semantic Correspondence as an Optimal Transport Problem},
author = {Liu, Yanbin and Zhu, Linchao and Yamada, Makoto and Yang, Yi},
booktitle = {CVPR},
year = {2020}
}
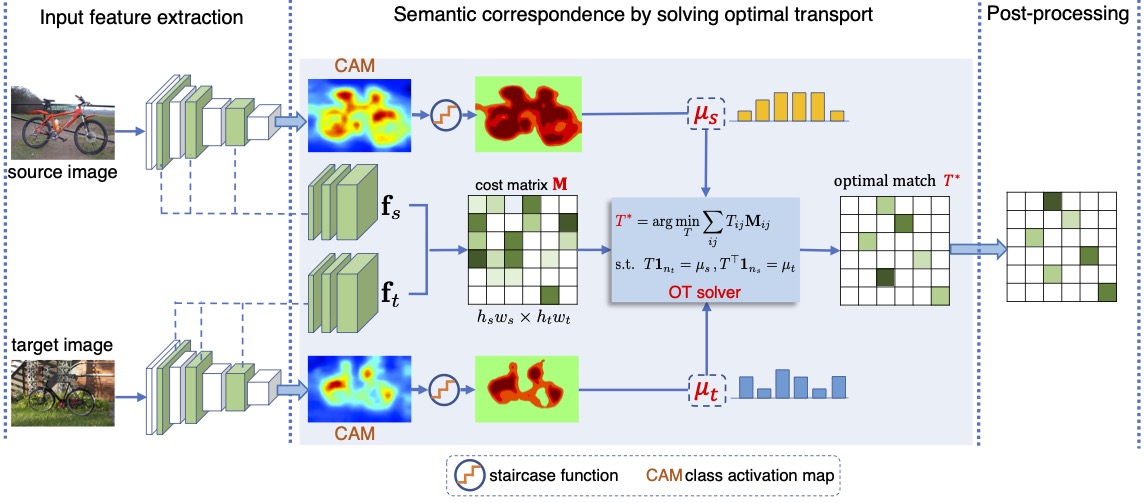
Establishing dense correspondences across semantically similar images is a challenging task. Due to the large intra-class variation and background clutter, two common issues occur in current approaches. First, many pixels in a source image are assigned to one target pixel, i.e., many to one matching. Second, some object pixels are assigned to the background pixels, i.e., background matching. We solve the first issue by global feature matching, which maximizes the total matching correlations between images to obtain a global optimal matching matrix. The row sum and column sum constraints are enforced on the matching matrix to induce a balanced solution, thus suppressing the many to one matching. We solve the second issue by applying a staircase function on the class activation maps to re-weight the importance of pixels into four levels from foreground to background. The whole procedure is combined into a unified optimal transport algorithm by converting the maximization problem to the optimal transport formulation and incorporating the staircase weights into optimal transport algorithm to act as empirical distributions. The proposed algorithm achieves state-of-the-art performance on four benchmark datasets. Notably, a 26\% relative improvement is achieved on the large-scale SPair-71k dataset.
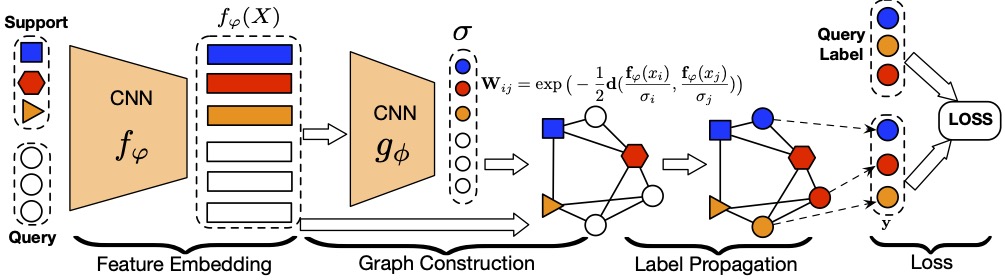
Yanbin Liu, Juho Lee, Minseop Park, Saehoon Kim, Eunho Yang, Sungju Hwang and Yi Yang
ICLR 2019.
@INPROCEEDINGS{liu2019learning,
title = {Learning to propagate labels: Transductive propagation network for few-shot learning},
author = {Liu, Yanbin and Lee, Juho and Park, Minseop and Kim, Saehoon and Yang, Eunho and Hwang, Sung Ju and Yang, Yi},
booktitle = {ICLR},
year = {2019}
}
The goal of few-shot learning is to learn a classifier that generalizes well even when trained with a limited number of training instances per class. The recently introduced meta-learning approaches tackle this problem by learning a generic classifier across a large number of multiclass classification tasks and generalizing the model to a new task. Yet, even with such meta-learning, the low-data problem in the novel classification task still remains. In this paper, we propose Transductive Propagation Network (TPN), a novel meta-learning framework for transductive inference that classifies the entire test set at once to alleviate the low-data problem. Specifically, we propose to learn to propagate labels from labeled instances to unlabeled test instances, by learning a graph construction module that exploits the manifold structure in the data. TPN jointly learns both the parameters of feature embedding and the graph construction in an end-to-end manner. We validate TPN on multiple benchmark datasets, on which it largely outperforms existing few-shot learning approaches and achieves the state-of-the-art results.

Yanbin Liu, Yan Yan, Ling Chen, Yahong Han and Yi Yang
AAAI 2019.
@INPROCEEDINGS{liu2019adaptive,
title = {Adaptive sparse confidence-weighted learning for online feature selection},
author = {Liu, Yanbin and Yan, Yan and Chen, Ling and Han, Yahong and Yang, Yi},
booktitle = {AAAI},
year = {2019}
}
In this paper, we propose a new online feature selection algorithm for streaming data. We aim to focus on the following two problems which remain unaddressed in literature. First, most existing online feature selection algorithms merely utilize the first-order information of the data streams, regardless of the fact that second-order information explores the correlations between features and significantly improves the performance. Second, most online feature selection algorithms are based on the balanced data presumption, which is not true in many real-world applications. For example, in fraud detection, the number of positive examples are much less than negative examples because most cases are not fraud. The balanced assumption will make the selected features biased towards the majority class and fail to detect the fraud cases. We propose an Adaptive Sparse Confidence-Weighted (ASCW) algorithm to solve the aforementioned two problems. We first introduce an l0-norm constraint into the second-order confidence-weighted (CW) learning for feature selection. Then the original loss is substituted with a cost-sensitive loss function to address the imbalanced data issue. Furthermore, our algorithm maintains multiple sparse CW learner with the corresponding cost vector to dynamically select an optimal cost. We theoretically enhance the theory of sparse CW learning and analyze the performance behavior in F-measure. Empirical studies show the superior performance over the stateof-the-art online learning methods in the online-batch setting.
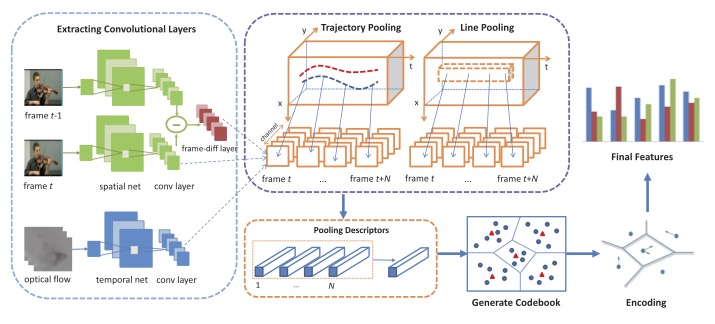
Shichao Zhao, Yanbin Liu, Yahong Han, Richang Hong, Qinghua Hu and Qi Tian
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT) 2018.
@ARTICLE{zhao2017pooling,
title = {Pooling the convolutional layers in deep convnets for video action recognition},
author = {Zhao, Shichao and Liu, Yanbin and Han, Yahong and Hong, Richang and Hu, Qinghua and Tian, Qi},
journal = {IEEE Transactions on Circuits and Systems for Video Technology},
volume = {28},
number = {8},
pages = {1839--1849},
year = {2021},
publisher = {IEEE},
doi = {10.1109/TCSVT.2017.2682196}
}
Deep ConvNets have shown their good performance in image classification tasks. However, there still remains problems in deep video representations for action recognition. On one hand, current video ConvNets are relatively shallow compared with image ConvNets, which limits their capability of capturing the complex video action information; on the other hand, temporal information of videos is not properly utilized to pool and encode the video sequences. Toward these issues, in this paper we utilize two state-of-the-art ConvNets, i.e., the very deep spatial net (VGGNet [1]) and the temporal net from Two-Stream ConvNets [2], for action representation. The convolutional layers and the proposed new layer, called frame-diff layer, are extracted and pooled with two temporal pooling strategies: Trajectory pooling and Line pooling. The pooled local descriptors are then encoded with vector of locally aggregated descriptors (VLAD) [3] to form the video representations. In order to verify the effectiveness of the proposed framework, we conduct experiments on UCF101 and HMDB51 data sets. It achieves accuracy of 92.08% on UCF101, which is the state-of-the-art, and the accuracy of 65.62% on HMDB51, which is comparable to the state-of-the-art. In addition, we propose the new Line pooling strategy, which can speed up the extraction of feature and achieve the comparable performance of the Trajectory pooling.
Teaching
Teaching Experiences- COMP838 Deep Learning, Auckland University of Technology, Lecturer 2024
- COMP701 Nature Inspired Computing, Auckland University of Technology, Lecturer 2024
- ENGN4528/COMP4528 Computer Vision, Australian National University, Co-Lecturer 2023
- COMP4680/COMP8650 Advanced Topics in Machine Learning, Australian National University, Guest Lecturer 2023
- 41025 Introduction to Software Development, University of Technology Sydney, Workshop Tutor 2023
Academic Service
Guest Editor- MDPI electronics, Special Issue “Multimedia Information Retrieval: From Theory to Applications”
- IEEE Transactions on Image Processing (TIP)
- IEEE Transactions on Knowledge and Data Engineering (TKDE)
- IEEE Transactions on Neural Networks and Learning Systems (T-NNLS)
- IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
- IEEE Transactions on Emerging Topics in Computational Intelligence (TETCI)
- International Journal of Computer Vision (IJCV)
- Transactions on Machine Learning Research (TMLR)
- Pattern Recognition (PR)
- ACM Transactions on Multimedia Computing, Communications and Applications (TOMM)
- Knowledge-Based Systems (KNOSYS)
- Neurocomputing (NEUCOM)
- ACM Multimedia 2024
- CVPR 2021 (Outstanding Reviewer), 2022-2024 (Outstanding Reviewer)
- ICLR 2022-2024
- ICCV 2021, 2023
- ICML 2020-2023
- NeurIPS 2020-2023
- AAAI 2021-2022
- IJCAI 2021
- AISTATS 2022-2024
Competitions
Google Cloud & YouTube-8M Video Understanding Challenge- Linchao Zhu, Yanbin Liu and Yi Yang
- Ranked top 1% (6/650) at YT8M leaderboard, our report pdf, code.
- Yanbin Liu, Baixiang Fan, Shichao Zhao, Youjiang Xu and Yahong Han
- Ranked 7th at the action recognition task.
- Yanbin Liu, Chengyue Zhang, Guang Li, Shichao Zhao, Youjiang Xu and Yahong Han
- Ranked 1st at the video retrieval track.
People
Friends & CollaboratorsLinchao Zhu (Zhejiang University), Juho Lee (KAIST), Makoto Yamada (Okinawa Institute of Science and Technology), Yan Yan (Washington State University), Xin Yu (University of Queensland)
